I have… four observations, regarding the Ngrams graph that’s shown on each etymology entry. Stipulating, up front, that (to quote the caption on each graph) “ngrams are probably unreliable”. Be that as it may, they must have been deemed better than nothing or they wouldn’t be included on the site. However, I think they could be better:
-
The caption for each graph, shown in poorly-contrasting gray text, reads:
adapted from books.google.com/ngrams/ with a 7-year moving average; ngrams are probably unreliable.
Google’s documentation page on NGrams, OTOH, says:
Ngram Viewer graphs and data may be freely used for any purpose, although acknowledgement of Google Books Ngram Viewer as the source, and inclusion of a link to https://books.google.com/ngrams, would be appreciated.
An unlinked “books.google.com/ngrams/” is not the same as a link to that page, and fails to actually make any “acknowledgement of Google Books Ngram Viewer as the source”, which doesn’t seem to meet the spirit of their request. Why not link to the URL mentioned, instead?
-
Better yet, why not link to the Ngram Viewer display of the actual graph being shown, so that users can experiment with modifications to the search terms? If Etymonline is embedding a graph with particular search terms, it shouldn’t be hard at all to generate a
https://books.google.com/ngrams/graph?link with those same search terms, and link that in the caption instead of the unlinked URL. (The link could also provide the requested acknowledgement, something like, on the etymonline page for “pule”:adapted from Google Books Ngram Viewer results for pule with a 7-year moving average; ngrams are probably unreliable
-
I notice that all of the graphs on etymonline only show data through 2019. That makes me think that etymonline is showing results from the older 2019 corpus. In July 2024, Google released a new dataset which contains results through 2022. That new corpus is the default for all searches run on the actual Ngram Viewer site, but the older one can still be requested by adding
:eng_2019to a search.(Though, it has to be said, neither searches for “pule” nor searches for “pule:eng_2019” produce data that matches what’s shown on etymonline, no matter what smoothing value I use. That lack of reproducibility, coupled with the lack of a link to the actual Ngrams results being displayed, makes it difficult to put much faith in the etymonline ngrams graphs, even relative to the questionable reliability of Google’s own graphs.)
-
While we’re on the topic of the Google results, though, Ngrams Viewer has another feature that could be extremely useful when embedding Ngrams graphs on etymonline in particular.
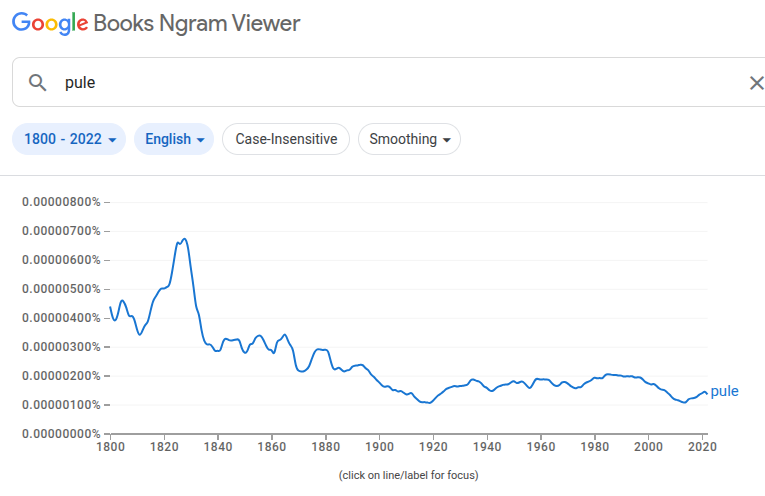
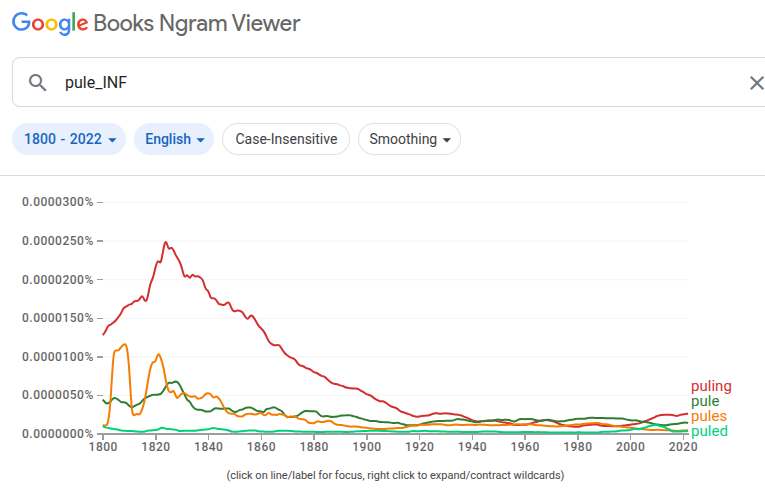
I chose “pule” as my example etymonline entry very deliberately, because it’s a verb that, for most of its history (though not always!) was much, much more commonly encountered in its adjective form: “puling”. Etymonline doesn’t maintain separate pages for the various forms of each entry, so the graph is seemingly only generated for the “primary” form? (Though as I noted in the previous item, I can’t really be sure where the data comes from.) Assuming that’s correct, though, primary-only searches can throw off the data for a term where some other form is far more common. But, Google has a solution for that: the inflection search, aka
_INF.The results of a search for “pule” with otherwise-default values:
The results of a search for “pule_INF”, instead:
Showing inflection-search results on the etymonline pages, instead of uninflected primary-form results, could make the graphs more informative for many entries.